最近做了一个很小、但对我自己挺有用的工具:VAT Invoice PDF Calculator。
它的功能很朴素:选择一个 PDF,扫描里面增值税电子发票二维码,解析金额,最后生成一个 CSV 汇总文件和一个带标记的 PDF,方便复核。
项目地址放在文末。
背景:为什么做这个工具
这个需求来自一个很具体的场景:有时候收到的发票不是一张张独立 PDF,而是被合并成一个 PDF。一个 PDF 可能有很多页,也可能在报销的时候,为了省钱,一页里排了多张电子发票。
如果只是偶尔处理一次,手工打开 PDF,看金额,再加总,也不是不能做。但这种事情一旦重复出现,就很容易出问题:
- 手工逐张核对很慢;
- 一页多张发票时容易漏;
- 重复发票不容易发现;
- 加总金额时也可能按错;
- 最后还要留一个结果给自己或别人复核。
所以我想做一个本地小工具,把最机械的部分自动化掉:能识别的自动算,不能识别的明确标出来,剩下交给人工复核。
这个定位很重要。它不是官方验票工具,也不是财务系统,只是一个帮助我减少重复劳动的小工具。
功能概览
现在这个工具大致支持:
- 选择单个 PDF 文件;
- 扫描每页中的发票二维码;
- 支持同一页存在多张发票;
- 解析二维码中的发票号码和价税合计金额;
- 自动跳过重复发票,不重复计入合计;
- 输出 UTF-8-BOM CSV,方便 Excel 打开;
- 生成一个标记 PDF;
- 在标记 PDF 里用红框标出已经识别到的二维码;
- 在每一页中间显示“本页扫描计算 N 张发票”;
- 对没有识别到二维码的页面,也在 CSV 中留下失败记录。
其中我觉得最有用的不是“自动算金额”本身,而是“可以复核”。因为二维码识别不是 100% 可靠,如果工具只给一个最终金额,其实会让人不放心。
技术选型
这个项目没有用很重的技术栈,基本都是够用就好:
- GUI:Python + Tkinter;
- PDF 渲染和标注:PyMuPDF;
- 二维码识别:pyzbar + zbar;
- CSV 输出:Python 标准库 csv;
- macOS 打包:PyInstaller。
Tkinter 的界面当然不华丽,但对这个工具来说足够了。它不需要账号系统,不需要数据库,不需要前后端分离,也不需要特别复杂的界面。选轻一点的方案,反而更符合这个项目的目标。
这里有一个容易踩坑的地方:pyzbar 只是 Python 包,它底层依赖系统里的 zbar。也就是说,只执行 pip install pyzbar 不一定够,还需要安装系统依赖。
在 macOS 上可以用:
brew install zbarApple Silicon Mac 上,Homebrew 通常会把 zbar 安装到 /opt/homebrew/lib。所以程序里也做了一些常见路径探测,尽量减少“明明安装了 zbar,运行时却找不到”的问题。
从“一页一张票”到“一页多张票”
第一版逻辑其实比较天真:默认一页 PDF 里最多只有一张发票。
后来实际测试时发现,这个假设不成立。有些 PDF 是把多张发票缩小排版到同一页里,一页可能有 2 张、4 张,甚至更多。这样原来的“每页一个结果”就不够用了。
于是我把解析逻辑改成了“每页可以返回多条发票结果”。
这个调整不只是多循环几次,它会影响整个数据模型:
page_number继续表示 PDF 页码;- 新增
qr_index,表示这是当前页第几个二维码; - 结果明细使用全局序号;
- 每页额外记录二维码统计;
- CSV 一页可能输出多行;
- 同一页内重复、跨页重复都用同一套去重规则。
这样改完以后,CSV 里就可以清楚看到:
- 第几页;
- 当前页第几个二维码;
- 本页一共检测到多少二维码;
- 本页有多少个成功解析为发票格式;
- 哪些成功、哪些重复、哪些失败。
这也是这个项目里比较典型的一次需求演化:不是加一个按钮,而是把“结果结构”从页级改成明细级。
二维码识别率与多倍率扫描
二维码识别这件事也比想象中麻烦。
有一页 PDF 里有 4 张发票,其中 3 个二维码很容易识别,右下角那个一开始识别不到。后来我用手机扫,发现它近距离也不好扫,但手机离远一点反而能扫出来。
这个现象说明:问题未必是二维码内容有错,也未必是 zbar 完全不行,可能和渲染尺寸、采样比例、二维码在页面里的实际像素大小有关。
一开始也想过要不要引入 OpenCV,做更多图像预处理。但后来觉得没有必要。这个工具的定位是轻量个人工具,引入 OpenCV 会让依赖和打包都变重,而且未必能明显提升这个场景的收益。
最后采用的是比较折中的办法:
- 用多个渲染倍率扫描同一页;
- 对整页扫描;
- 对页面区域做分区扫描;
- 对 zbar 返回的二维码原始数据去重;
- 最后取合并后的结果。
这不是万能方案,但对“二维码太小、缩放后更容易识别”的 PDF 比较有效。
也就是说,工具会尽量多识别,但不会假装自己能识别所有二维码。
为什么要生成标记 PDF
后来我意识到,只输出 CSV 还不够。
如果工具说“我识别了 45 张发票”,但原 PDF 里其实有 52 张,那用户怎么知道漏掉的是哪几张?如果 zbar 根本没有检测到某个二维码,程序也就不知道那个位置存在一张未识别发票。
所以我加了一个标记 PDF。
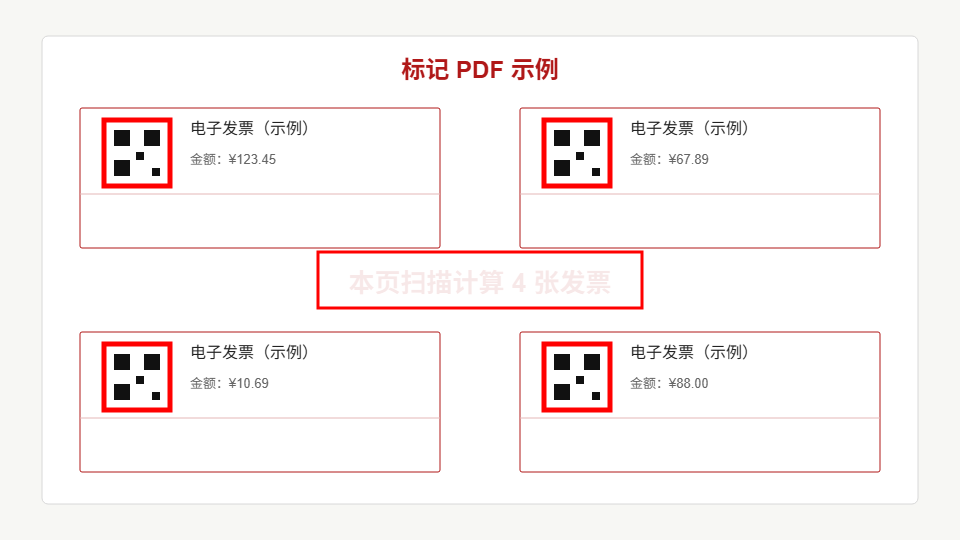
标记 PDF 不修改原始文件,而是在原 PDF 同目录生成一个新文件。已经识别到的二维码会被红框标出来,每一页中间会显示:
本页扫描计算 N 张发票这样复核时就很直观:
- 被红框标出的,说明工具识别到了;
- 没有红框的发票,需要人工看一下;
- 页面中间的数量可以和肉眼看到的发票数量对比。
这个设计承认了一个事实:自动识别会失败。与其把失败藏起来,不如把工具的识别范围明确画出来。
我觉得这类小工具里,“暴露不确定性”比“假装全自动”更重要。
CSV 输出与重复发票处理
CSV 的目标也很简单:让人能打开、检查、留档。
输出文件使用 UTF-8-BOM,这样在 Excel 里打开中文列名不容易乱码。每条记录包含页码、页内二维码序号、二维码统计、发票号码、原始二维码内容、解析状态和金额。
重复发票不会计入合计。
比如同一张发票在 PDF 里出现两次,第一条会被视为成功,后面相同发票号码会标记为重复。这样既能在 CSV 里看见重复记录,又不会把金额加两遍。
当前输出文件名是固定规则:
原文件名_发票汇总.csv
原文件名_识别标记.pdf如果同目录下已经存在同名输出文件,会被新的结果覆盖。原始 PDF 不会被修改。
zbar 依赖与 Apple Silicon 支持
这个项目目前主要在 Apple Silicon Mac 上开发和测试。
比较明确的支持状态是:
| 平台 | 状态 |
|---|---|
| Apple Silicon macOS | 已开发和测试 |
| Intel macOS | 未测试 |
| Windows | 未测试 |
| Linux | 未测试 |
我没有在 README 里写“跨平台支持”,因为那样不诚实。Python 代码理论上可以在其他平台跑,但 zbar、PDF 渲染、GUI 和打包都会涉及平台差异,没有测试过就不能承诺。
如果只是从源码运行,Apple Silicon Mac 上大致是:
brew install zbar
python3 -m venv .venv
.venv/bin/python -m pip install -r requirements.txt
.venv/bin/python main.py打包成 .app 也可以做,但这次 GitHub release 我没有上传 .app,只发布源码。原因是 .app 涉及签名、公证、zbar 动态库路径等问题,如果处理得不够完整,反而容易给别人造成误导。
隐私与开源前清理
这个项目处理的是发票 PDF,所以隐私清理必须认真做。
开源前我做了几件事:
- 不提交真实发票 PDF;
- 不提交生成的 CSV;
- 不提交标记 PDF;
- 不提交
.venv、build、dist、缓存目录; - README 和测试里的发票号码全部换成 fake data;
- 增加
.gitignore; - 扫描仓库里的敏感关键词;
- 检查 GitHub private 仓库后再准备公开。
这里还有一个很容易忽略的问题:Git 历史。
即使当前文件已经改成假数据,如果之前的 commit diff 里出现过真实发票号码,公开后仍然可能泄露。所以这类项目公开前,不能只看当前文件,还要检查历史、tag 和 release。
对个人项目来说,如果没有保留开发历史的必要,最干净的做法是:为公开仓库准备一个干净历史的初始提交。
当前限制
这个工具目前还有不少限制:
- 只在 Apple Silicon macOS 上测试过;
- 不保证识别所有发票格式;
- 不保证识别所有低质量二维码;
- 不校验发票真伪;
- zbar 如果完全检测不到某个二维码,程序无法知道那个二维码的位置;
- 输出 CSV 和标记 PDF 会覆盖同名旧文件;
- 当前 release 只发布源码,不提供可直接安装的
.app。
这些限制我都写进了 README。小工具可以简单,但公开出来以后,边界最好说清楚。
总结
这个项目不复杂,但它对我来说是一个挺完整的小闭环:
从一个真实的手工重复劳动开始,做了一个能跑的 GUI 工具;遇到一页多张发票的问题,就调整数据结构;遇到二维码识别率问题,就用多倍率扫描提高成功率;遇到无法识别的情况,就生成标记 PDF,把问题交还给人工复核;最后再把项目整理成可以公开的开源仓库。
我喜欢这种项目的原因是,它不是为了展示某个框架,也不是为了堆功能,而是从一个具体问题出发,把边界、失败情况和使用体验都稍微照顾到。
工具不需要替人做所有判断。它只要把最容易重复、最容易漏、最不值得手工做的部分接过去,就已经很有价值了。